Wprowadzenie
W aplikacjach bardzo często używamy zewnętrznych zasobów. A to trzeba wykonać zapytanie na bazie danych, pobrać dane z usługi lub wysłać wiadomość e-mail. Zasoby te charakteryzują się tym, że mogą być przez jakiś czas niedostępne, bo na przykład wystąpił jakiś problem z siecią lub zasób jest zbyt mocno obciążony. W takich sytuacjach zastanawiamy się, czy od razu pokazać użytkownikowi informacje o błędzie, czy może spróbować ponowić operację po jakimś czasie i dopiero po którejś próbie pokazać błąd. Ten drugi sposób jest na ogół pożądanym podejściem. W dzisiejszym wpisie pokażę Ci, jak łatwo i przyjemnie ponawiać operacje w momencie wystąpienia błędu (np. wyjątku) z wykorzystaniem biblioteki Polly (https://github.com/App-vNext/Polly).
Pobranie danych z Internetu
Do przetestowania biblioteki wykorzystamy klasę WebClient, która umożliwia pobieranie danych z internetu. Przykład tym razem nie będzie za bardzo rozbudowany. Będzie to prosta aplikacja konsolowa, która pobierze html z głównej strony tego bloga:
| class Program | |
| { | |
| private static NLog.Logger _logger = NLog.LogManager.GetCurrentClassLogger(); | |
| static void Main(string[] args) | |
| { | |
| _logger.Info("Start"); | |
| try | |
| { | |
| var content = Download("https://plawgo.pl"); | |
| _logger.Info("Success"); | |
| } | |
| catch (Exception ex) | |
| { | |
| _logger.Fatal(ex, "Error"); | |
| } | |
| _logger.Info("End"); | |
| } | |
| static string Download(string url) | |
| { | |
| var client = new WebClient(); | |
| return client.DownloadString(url); | |
| } | |
| } |
Nie ma tutaj nic skomplikowanego. Aplikacja za pomocą nloga wypisuje komunikaty na konsoli (jest ona ustawiona jako target w Nlog.config). Metoda Download pobiera string z przekazanego adresu i jest wywołana w bloku try-catch, który wyświetla informacja o tym, czy udało się pobrać htmla, czy nastąpił błąd.
W normalnej sytuacji bez błędu aplikacja wyświetli coś takiego:

Symulowanie błędów sieci
Aby przetestować w praktyce działanie Polly, będziemy musieli kontrolować połączenie sieciowe. Podczas testów możemy się fizycznie odłączać od sieci, ale takie podejście na dłuższą metę jest problematyczne. Dlatego skorzystamy z gotowej aplikacji, która umożliwia symulowanie różnych problemów z działaniem sieci. Aplikacja nazywa się clumsy (https://jagt.github.io/clumsy/). Wystarczy ją pobrać, wypakować i uruchomić z uprawnieniami administratora. Co fajne, nie trzeba nic konfigurować, dodawać proxy itp. Uruchamiamy i działa.
Do przetestowania Polly skorzystamy z funkcji Drop, która oznacza zbyt długi czas odpowiedzi serwera. W testach ustawiłem, aby timeout występował z szansą 75%. Dodatkowo warto jeszcze ustawić filtr, aby aplikacja blokowa pokazywała tylko żądania wysyłane do testowego serwera, a nie wszystkie połączenia w systemie. Można zrobić to za pomocą filtru na górze. Podczas pisania tego wpisu korzystałem z filtru:
| outbound and ip.DstAddr >= 185.255.40.24 and ip.DstAddr <= 185.255.40.24 |
Z czasem adres IP serwera, na którym jest blog, może się zmienić, więc warto wcześniej to sprawdzić.
Dokładna konfiguracja clumsy wygląda tak:
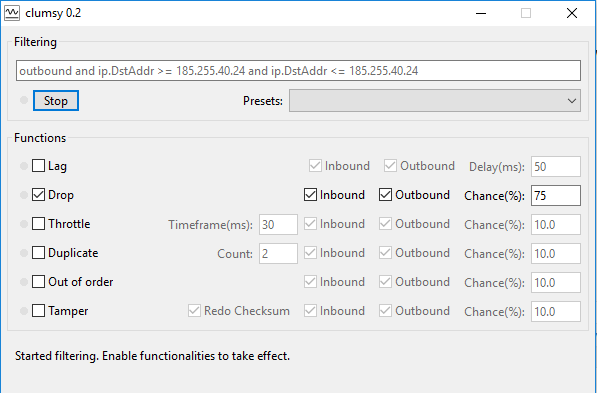
Po uruchomieniu i skonfigurowaniu clumsy testowa aplikacja wykona się tak (o ile oczywiście trafimy w te 75% problematycznych żądań :)):

Ponawianie operacji z Polly
Biblioteka Polly (https://github.com/App-vNext/Polly) jest jedną z ciekawszych opcji do ponawiania operacji. Możemy ją wykorzystać w standardowym .NET, jak i w wersji Core, w różnych frameworkach. Sama praca z biblioteką jest prosta i składa się generalnie z trzech kroków:
- Określenia błędu lub sytuacji, którą chcemy obsłużyć – np. wyjątku lub wyniku metody
- Zdefiniowania, co ma się stać, gdy nastąpiła sytuacja z punktu pierwszego – np. trzykrotne ponowienie operacji
- Samego wywołania operacji, której ma dotyczyć zdefiniowana reguła.
Najlepiej działanie biblioteki zobaczyć w praktyce. Poniżej znajduje się fragment kodu, który do wcześniejszej metody pobierania htmla z internetu dodaje trzykrotne ponowienie operacji w momencie, gdy zostanie wyrzucony WebException:
| static string DownloadWithRetry(string url) | |
| { | |
| var client = new WebClient(); | |
| return Policy | |
| .Handle<WebException>() | |
| .Retry(3, (ex, retryCount) => | |
| { | |
| _logger.Error(ex, $"Error - try retry (count: {retryCount})"); | |
| }) | |
| .Execute(() => client.DownloadString(url)); | |
| } |
Powyżej w kodzie widać wspomniane trzy kroki:
- Handle – rodzaj wyjątku, dla którego tworzymy regułę
- Retry – określa, co ma się stać, gdy będzie wyjątek – w tym przypadku trzykrotna próba ponowienia operacji – dodatkowo dodanie do logu stosownej informacji
- Execute – uruchamia właściwą metodę, która pobiera html i do której zostanie zastosowana reguła
Poniżej zrzut ekranu, na którym widać, jak zadziałała powyższa reguła. Wystąpił jeden błąd i operacja została ponowiona:

Ponawianie z czekaniem
Metoda Retry z wcześniejszego przykładu, w momencie gdy pojawi się błąd, od razu ponawia operację. Czasami takie zachowanie jest tym, czego potrzebujemy, natomiast bardzo często takie zachowanie może powodować dodatkowe problemy. Gdy serwer, do którego wysyłamy żądania, jest obciążony, taki sposób ponawiania może dodatkowo obciążyć go jeszcze bardziej. Dlatego definiując reguły w Polly, warto zastanowić się, czy powinniśmy od razu ponowić operację, czy może chwilkę poczekać.
Czekanie daje serwerowi czas, aby obsłużył wszystkie aktualne operacje bez dodawania mu kolejnych rzeczy do wykonania. Warto to rozważyć, szczególnie że w Polly definiuje się to bardzo łatwo:
| static string DownloadWithRetryAndDelay(string url) | |
| { | |
| var client = new WebClient(); | |
| return Policy | |
| .Handle<WebException>() | |
| .WaitAndRetry(new[] | |
| { | |
| TimeSpan.FromSeconds(10), | |
| TimeSpan.FromSeconds(20), | |
| TimeSpan.FromSeconds(50) | |
| }, (ex, timeSpan, retryCount, context) => | |
| { | |
| _logger.Error(ex, $"Error - try retry (count: {retryCount}, timeSpan: {timeSpan})"); | |
| }) | |
| .Execute(() => client.DownloadString(url)); | |
| } |
Zamiast z metody Retry korzystamy z metody WaitAndRetry. Do metody tej przekazujemy informacje o czasie, jaki powinien minąć między poszczególnymi próbami. Czas ten możemy przekazać w postaci tablicy jak powyżej lub delegatu, który będzie obliczał kolejne okresy czekania. Poniżej wynik działania testowej aplikacji. Zwróć uwagę, że czas między poszczególnymi próbami się zwiększa:

Ponawianie operacji w nieskończoność
Innym sposobem ponawiania operacji jest próba wykonywania jej w nieskończoność. Taki sposób ponawiania operacji również może być przydatny w aplikacji. Czasami mamy specjalną akcję w systemie, która służy do monitorowania, czy usługa lub inny zasób, z którego korzystamy, jest dostępny (np. metoda Ping, która pinguje serwer co 1 minutę). W momencie gdy serwer przestaje odpowiadać, możemy zablokować wszystkie wywołania poza tą specjalną metodą. Wywołanie pinga ponawiamy w nieskończoność do momentu odpowiedzi. Gdy serwer zacznie odpowiadać, możemy wznowić wszystkie operacje.
Aby dodać ponawianie w nieskończoność, wystarczy skorzystać z innej metody w regule Polly. RetryForever może próbować wykonywać operację ponownie od razu po błędzie (tak jak w przykładzie poniżej); możemy dodać też opóźnienia między poszczególnymi próbami, tak jak w WaitAndRetry.
| static string DownloadWithRetryForever(string url) | |
| { | |
| var client = new WebClient(); | |
| return Policy | |
| .Handle<WebException>() | |
| .RetryForever(ex => | |
| { | |
| _logger.Error(ex, $"Error - try retry forever"); | |
| }) | |
| .Execute(() => client.DownloadString(url)); | |
| } |
Kilka kolejnych prób w testowej aplikacji:

Hangfire vs Polly
Kilka tygodni temu opisywałem użycie biblioteki Hangfire (na przykładzie wysyłki e-mail w tle). Obie biblioteki służą w pewnym sensie do ponawiania operacji. Hangfire w momencie błędu również po jakimś czasie wykonuje zadanie jeszcze raz. Kiedy więc używam Hangfire, a kiedy Polly?
Hangfire służy mi do wykonywania większych (takich bardziej biznesowych) zadań. Dobrym przykładem jest właśnie wysyłka wiadomości e-mail. Jest to takie większe zadanie, które na ogół składa się z kilku różnych kroków. Na przykład wysłanie wiadomości potwierdzającej założenie konta (w Hangfire mamy tylko zapisane ID nowego użytkownika) będzie składać się z następujących kroków: pobranie danych z bazy o użytkowniku, wygenerowanie treści wiadomości oraz jej wysyłka.
Polly natomiast wykorzystuję do operacji niskopoziomowych, które na ogół wchodzą w skład czegoś większego. W przykładzie z wysyłką ee-mail Polly użyłbym w dwóch miejscach: do ponawiania pobraniach danych użytkownika z bazy oraz samej wysyłki wiadomości.
Jak widać, można w fajny sposób połączyć działanie tych dwóch bibliotek w jeden niezawodny system.
Przykład
Kod przykładu znajduje się w repozytorium na githubie: https://github.com/danielplawgo/PollyExample. Po pobraniu przykładu w metodzie Main należy zmienić wywołanie testowych metod w zależności od tego, co chcesz testować. Pamiętaj, żeby w jakiś sposób (np. za pomocą clumsy) zablokować dostęp do serwera, aby wystąpił wyjątek. Wtedy będziesz mógł sprawdzić działanie biblioteki w praktyce.
Podsumowanie
Niezawodność działania jest jednym z istotnych elementów podczas tworzenia aplikacji. Jest to istotne szczególnie gdy coraz popularniejsze staje się rozbijanie dużych systemów na mniejsze mikro serwisy, które komunikują się z sobą. W takim środowisku ponawianie operacji jest bardzo ważne.
Dlatego warto zainteresować się biblioteką Polly, który umożliwia dodanie ponawiania w prosty i przyjemny sposób. Sama biblioteka posiada dużo większe możliwości niż to, co pokazałem w tym wpisie. Dlatego gorąco zachęcam do przejrzenia jej dokumentacji na stronie https://github.com/App-vNext/Polly.
W jednym w kolejnych wpisów pokażę, jak można dodać takie ponawianie transparentnie z wykorzystaniem interceptorów w Autofac.
W artykule zabrakło polityki „CircuitBreaker” ale ona zasługuje na osobny artykuł. Jeżeli taki popełnisz chętnie go przeczytam 🙂
Taki jest plan, aby o CircuitBreaker napisać osobny artykuł.
Dzięki fajny artykuł. Nigdy wcześniej o tej bibliotece nie słyszałem a wyobraźnia podpowiada mi wiele zastosować 🙂
Super, że się podoba 🙂 We wtorek będzie wpis o tym, jak jeszcze innej (według mniej fajniej) można użyć Polly w projekcie 🙂
Fajny artykuł i przydatna biblioteka 😉
Dzięki!
Bardzo fajny artykuł. O ile polly znałem to clumsy przetestuję przy najbliższej okazji