Wprowadzenie
Używanie kontenerów bardzo ułatwia lokalne programowanie. W szczególności gdy nasz projekt jest rozbudowany i wykorzystuje różne elementy infrastrukturalne, takie jak baza danych, storage, kolejki i tym podobne rzeczy. Dzięki dockerowi możemy w kilka chwil postawić lokalne środowisko do pracy bez konieczności spędzania długich godzin na instalowaniu niezbędnych komponentów. W tym wpisie pokażę Ci, w jaki sposób postawić w dockerze SQL Server, jak go skonfigurować, a na końcu zobaczysz również, jak utworzyć testowe bazy danych ze skryptów sql podczas uruchamiania kontenera z bazą.
SQL Server i Docker
Kontenery od dłuższego czasu są standardem i zakładam, że się z nimi już spotkałeś. W samym wpisie chciałbym się skupić przede wszystkim na uruchamianiu SQL Servera w kontenerze, niż na samych podstawach działania kontenerów. W tym wpisie użyję kontenerów oparty do Linuxa, których używamy w przeważającej większości.
Do uruchomienia SQL Servera wykorzystam docker-compose, szczególnie że na ogół w projekcie wykorzystujemy kilka różnych elementów infrastruktury i mając jeden plik docker-compose.yml możemy je później uruchomić jedną komendą.
Najbardziej podstawowa wersje docker-compose.yml dla SQL Server wygląda tak:
| version: "3.9" | |
| services: | |
| db: | |
| container_name: sql-server-db | |
| image: mcr.microsoft.com/mssql/server:2019-latest | |
| environment: | |
| SA_PASSWORD: Your_password123 | |
| ACCEPT_EULA: Y | |
| ports: | |
| - 1433:1433 |
Poszczególne linijki określają:
- wersję formatu pliku
- sekcję określającą usługi – SQL Server będzie udostępniony jako usługa
- nazwę usługi – db – używana później na przykład do komunikacji między kontenerami
- nazwę kontenera – sql-server-db
- obraz kontenera – korzystamy z najnowszego obrazu SQL Server 2019
- sekcję ze zmiennymi środowiskowymi, która skonfiguruje serwer
- zmienną środowiskową SA_PASSWORD, która służy do ustawienia hasła dla użytkownika sa – wykorzystamy to później do połączenia się z serwerem
- zmienną środowiskową ACCEPT_EULA służy do akceptacji licencji serwera, jest to wymagane
- sekcję konfigurującą mapowanie portów – określa jaki port hosta (wartość przed 🙂 będzie zmapowany z portem kontenera (wartość po :), umożliwi nam to komunikację z hosta z kontenerem, w tym przypadku na przykład możliwość połączenia się z serwerem za pomocą SQL Management Studio
- mapowanie portu 1433 hosta na port 1433 kontenera – czyli udostępnienie domyślnego portu SQL do komunikacji
Uruchomienie SQL Servera w kontenerze
Mając tak przygotowany plik docker-compose.yml, możemy uruchomić kontener z SQL Serverem poprzez wykonanie w wierszu poleceń komendy:
docker-compose upZa pierwszym razem wykonanie tej komendy może zająć dłuższą chwilę. Jest to spowodowane tym, że docker musi pobrać obraz z repozytorium, co zajmuje chwilę. Po jakimś czasie na konsoli zobaczymy szereg logów z SQL Servera, co świadczy o tym, że kontener działa i serwer w nim również:
Teraz możemy połączyć się z SQL Serverem, na przykład używając SQL Management Studio:
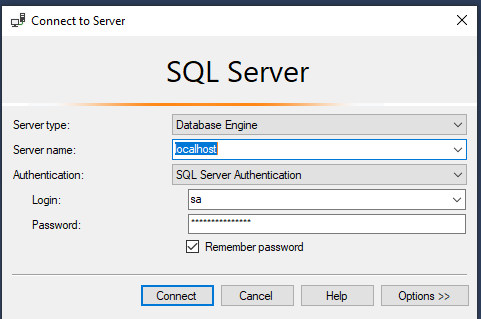
Adres serwera to localhost, używamy tutaj domyślnego portu 1433. Login to sa i hasło podane w zmiennej środowiskowej SA_PASSWORD z docker-compose.yml. W tym momencie możemy korzystać z serwera w normalny sposób, tak jak gdyby był zainstalowany normalnie w systemie.
Wolumeny
Aktualna konfiguracja kontenera powoduje, że utworzone bazy danych w SQL Serverze są fizycznie przechowywane w kontenerze. Usunięcie kontenera powoduje usunięcie baz danych. Docker udostępnia wolumeny, za pomocą których możemy zamontować folder z hosta w kontenerze. Plusem wolumenów jest to, że ich cykl życia jest niezależny od kontenera. Czyli jego usunięcie nie powoduje usunięcia plików z wolumenu. Minusem jest narzut wydajnościowy, który podczas developmentu nie jest odczuwalny.
Wolumeny przydają się również w sytuacji, gdy chcemy przekazać jakieś pliki z hosta do kontenera. Na przykład pliki backup baz danych, czy skryptów sql, które mają się wykonać na bazie. W dalszej części wpisu wykorzystamy wolumeny właśnie do przekazania skryptów do wykonania przy starcie kontenera.
Do wcześniejszej konfiguracji usługi w docker-compose.yml dodam teraz dwa wolumeny. Pierwszy to folder z danymi, natomiast drugi to folder z logami. Mapowane są one do folderu sqlserver, który jest w tym samym folderze co plik docker-compose.yml. Folder ten jest ignorowany w gicie.
Zaktualizowana konfiguracja wygląda tak. Trzy ostatnie linie to konfiguracja wolumenów:
| version: "3.9" | |
| services: | |
| db: | |
| container_name: sql-server-db | |
| image: mcr.microsoft.com/mssql/server:2019-latest | |
| environment: | |
| SA_PASSWORD: Your_password123 | |
| ACCEPT_EULA: Y | |
| ports: | |
| - 1433:1433 | |
| volumes: | |
| - ./sqlserver/data:/var/opt/mssql/data | |
| - ./sqlserver/log:/var/opt/mssql/log |
Po uruchomieniu kontenera w folderze sqlserver/data znajdziesz szereg plików baz danych, na przykład master.mdf:
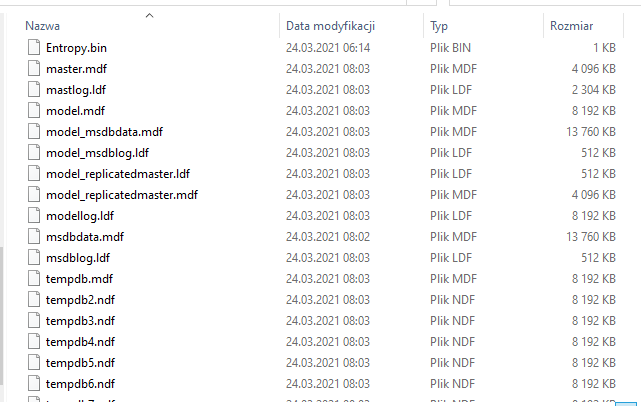
W tym folderze później pojawia się pliki nowych baz danych, które utworzymy.
Uruchomienie skryptów po starcie kontenera
Ostatnią rzeczą, jaką będę chciał Ci pokazać, jest możliwość wykonana skryptów zaraz po uruchomienia kontenera. Przydaje się to w sytuacji, gdy chcemy mieć jakieś testowe dane w nowo utworzonym kontenerze. Dzięki temu, na przykład, nowa osoba w projekcie może uruchomić kontenery i będzie miała już skonfigurowaną bazę danych z danymi testowymi.
W przykładzie skrypty będą znajdowały się w folderze scripts, który jest elementem repozytorium. Ale równie dobrze mogą być one pobrane z jakiegoś serwera, w sytuacji gdy nie chcemy ich przechowywać w repozytorium.
Osobiście co jakiś czas zrzucam zawartość bazy testowej do takiego skryptu, który później jest uruchamiany u każdego z programistów w lokalnym środowisku. Dzięki temu wszyscy pracują mniej więcej na tych samych danych i nie tracą czasu na ich przygotowanie. A do tego wszystko dzieje się automatycznie podczas uruchamiania komendy docker-compose up.
Aby to osiągnąć poza dodaniem folderu scripts oraz plików sql do niego, musimy jeszcze odpowiednio zmienić plik docker-compose.yml:
| version: "3.9" | |
| services: | |
| db: | |
| container_name: sql-server-db | |
| image: mcr.microsoft.com/mssql/server:2019-latest | |
| environment: | |
| SA_PASSWORD: Your_password123 | |
| ACCEPT_EULA: Y | |
| ports: | |
| - 1433:1433 | |
| volumes: | |
| - ./sqlserver/data:/var/opt/mssql/data | |
| - ./sqlserver/log:/var/opt/mssql/log | |
| - ./scripts:/scripts/ | |
| command: | |
| - /bin/bash | |
| - -c | |
| - | | |
| # Launch MSSQL and send to background | |
| /opt/mssql/bin/sqlservr & | |
| pid=$$! | |
| # Wait for it to be available | |
| echo "Waiting for MS SQL to be available ⏳" | |
| /opt/mssql-tools/bin/sqlcmd -l 30 -S localhost -h-1 -V1 -U sa -P $$SA_PASSWORD -Q "SET NOCOUNT ON SELECT \"YAY WE ARE UP\" , @@servername" | |
| is_up=$$? | |
| while [ $$is_up -ne 0 ] ; do | |
| echo -e $$(date) | |
| /opt/mssql-tools/bin/sqlcmd -l 30 -S localhost -h-1 -V1 -U sa -P $$SA_PASSWORD -Q "SET NOCOUNT ON SELECT \"YAY WE ARE UP\" , @@servername" | |
| is_up=$$? | |
| sleep 5 | |
| done | |
| # Run every script in /scripts | |
| # TODO set a flag so that this is only done once on creation, | |
| # and not every time the container runs | |
| for foo in /scripts/*.sql | |
| do /opt/mssql-tools/bin/sqlcmd -U sa -P $$SA_PASSWORD -l 30 -e -i $$foo | |
| done | |
| # trap SIGTERM and send same to sqlservr process for clean shutdown | |
| trap "kill -15 $$pid" SIGTERM | |
| # Wait on the sqlserver process | |
| echo "All scripts have been executed. Waiting for MS SQL(pid $$pid) to terminate." | |
| # Wait on the sqlserver process | |
| wait $$pid | |
| exit 0 |
W pliku pojawiły się dwie zmiany. W linijce 14 pojawił się nowy wolumen. Jest to zamontowanie folderu scripts z repozytorium w kontenerze. Jest to potrzebne, aby pliki były dostępne z poziomu kontenera.
Natomiast od linijki 15 znajduje się definicja sekcji command, która robi całą magię. Nie będę tego tutaj szczegółowo opisywał. Rozwiązanie zaczerpnięte jest z wątku na githubie https://github.com/microsoft/mssql-docker/issues/11, gdzie jest więcej informacji. W skrócie startujemy SQL Server, czekamy na jego uruchomienie. Gdy to nastąpi to kolejno są wykonywane pliki *.sql z folderu script. Ostatnim etapem jest czekanie na zakończenie procesu SQL Servera, który kończy się wraz z sygnałem zamknięcie kontenera.
Tutaj warto, aby skrypty były tak zbudowane, aby mogły być wykonane na pustej bazie danych, jak i na istniejącej. Więc warto sprawdzić, czy baza istnieje, podobnie różne elementy bazy. W przykładzie użyłem takiego oto skryptu:
| IF NOT EXISTS(SELECT * FROM sys.databases WHERE name = 'Database1') | |
| BEGIN | |
| CREATE DATABASE [Database1] | |
| END | |
| GO | |
| USE [Database1] | |
| GO | |
| --You need to check if the table exists | |
| IF NOT EXISTS (SELECT * FROM sysobjects WHERE name='Users' and xtype='U') | |
| BEGIN | |
| CREATE TABLE Users ( | |
| Id INT PRIMARY KEY IDENTITY (1, 1), | |
| Name VARCHAR(100) | |
| ) | |
| END |
Dla każdej bazy mam dedykowany skrypt, który jest odpowiedzialny za jej przygotowanie. Dzięki temu nie mam problemów z kolejnością wykonywanych skryptów.
Przykład
Na githubie znajduje się cały przykład – https://github.com/danielplawgo/SqlServerAndDocker. Do jego uruchomienia potrzebny jest zainstalowany docker. Po pobraniu przykładu wystarczy w folderze głównym wykonać komendę docker-compose up. Po jakimś czasie kontener się uruchomi i znajdować się będą w nim dwie bazy utworzone przez skrypty z folderu script.
Podsumowanie
Docker i kontenery bardzo ułatwiają lokalne programowanie i stawianie środowiska. W efekcie jesteśmy w stanie wszystko postawić jedną komendą. Oczywiście wcześniej trzeba przygotować plik docker-compose.yml, ale nie jest to jakoś mocno skomplikowane. A zainwestowany czas bardzo szybko się zwraca.
Szkolenie Mikroserwisy w .NET 5

Zainteresował Ciebie ten temat? A może chcesz więcej? Jak tak to zapraszam na moje autorskie szkolenie o tworzeniu mikroserwisów w .NET.
Super wpis, czy możesz też opisać robienie kopii (archiwum) z dockera na komputerze z windowsem? Mam InsertGT i nie mogę stworzyć archiwum.
Dzięki, a co do prośby to zapisuje sobie to na liście tematów 🙂
Witam.
Bardzo fajny wpis. Od kilku miesięcy używam Dockera z MS SQL do testowania specyficznych ficzerów z linq2db (chociażby merge). Zwrócę tylko uwagę na jedną rzecz. Otóż powodzenie w uruchomieniu skryptów .sql zależy od tego czy kontener Dockera jest na Windowsie czy LInuxie, gdyż wówczas mamy do czynienia z innymi znakami końca linii. Wydaje się to oczywiste, ale może być nietrywialne do prześledzenia gdy np. kontener wstaje poprawnie, ale bez stworzenia Usera, jak w powyższym przykładzie.
Pozdrawiam.
Hej dzięki za komentarz! Tutaj faktycznie mogłem zaznaczyć, że mówimy o kontenerach uruchomionych na linuxie. Już to dodaje do wpisu.